| CPC A63F 13/87 (2014.09) [A63F 13/355 (2014.09); A63F 13/71 (2014.09); A63F 13/77 (2014.09); A63F 13/79 (2014.09)] | 20 Claims |
|
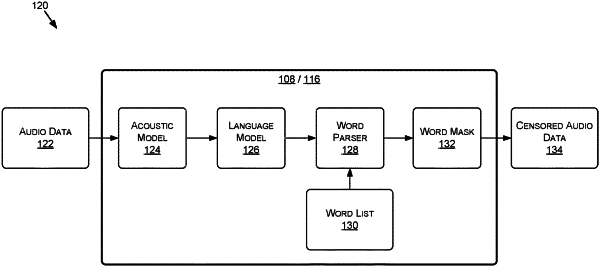
1. A method comprising:
applying, to one or more first models, audio data generated using one or more microphones and during a session associated with a gaming application;
determining, using the one or more first models, a sequence of characters corresponding to a textual representation of the audio data;
generating, using one or more second models and based at least on the textual representation, an output that classifies at least a portion of the sequence of characters as inappropriate;
determining a portion of the audio data corresponding to the at least the portion of the sequence of characters; and
executing one or more actions with respect to the portion of the audio data.
|