| CPC G10L 17/06 (2013.01) [G10L 17/02 (2013.01); G10L 17/18 (2013.01); G10L 25/18 (2013.01); G10L 25/21 (2013.01)] | 20 Claims |
|
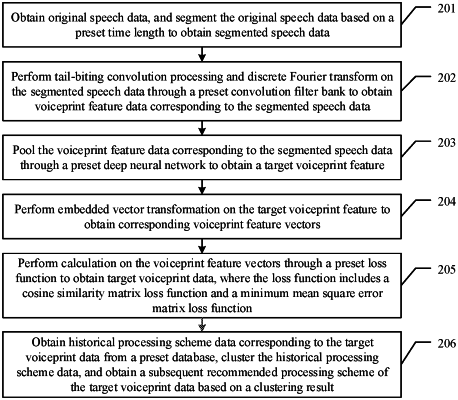
1. A method for a voiceprint recognition of an original speech, comprising:
obtaining original speech data, and segmenting the original speech data based on a preset time length to obtain segmented speech data;
performing a tail-biting convolution processing and a discrete Fourier transform on the segmented speech data through a preset convolution filter bank to obtain voiceprint feature data corresponding to the segmented speech data;
pooling the voiceprint feature data corresponding to the segmented speech data through a preset deep neural network to obtain a target voiceprint feature;
performing an embedded vector transformation on the target voiceprint feature to obtain voiceprint feature vectors corresponding to the target voiceprint feature; and
performing a calculation on the voiceprint feature vectors through a preset loss function to obtain target voiceprint data, wherein the preset loss function comprises a cosine similarity matrix loss function and a minimum mean square error matrix loss function.
|