| CPC G06V 20/58 (2022.01) [G01S 17/42 (2013.01); G01S 17/89 (2013.01); G01S 17/931 (2020.01); G06F 18/217 (2023.01); G06F 18/2113 (2023.01); G06F 18/2155 (2023.01); G06F 18/251 (2023.01); G06N 3/04 (2013.01); G06N 3/08 (2013.01); G06N 20/00 (2019.01); G06T 7/10 (2017.01); G06T 7/11 (2017.01); G06T 7/50 (2017.01); G06V 10/462 (2022.01); G06V 10/757 (2022.01); G06V 20/56 (2022.01); G06T 2207/10024 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20016 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30248 (2013.01)] | 20 Claims |
|
1. A system comprising:
a processor; and
a memory in communication with the processor, the memory having a training set generation module having instructions that, when executed by the processor, cause the processor to:
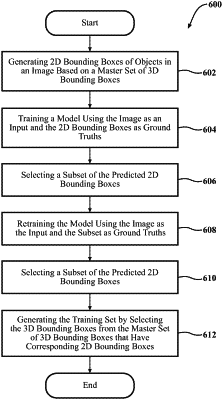
generate 2D bounding boxes of objects in an image based on a master set of 3D bounding boxes of the objects,
train a model using the image as an input and the 2D bounding boxes as ground truths, wherein the model outputs a first set of predicted 2D bounding boxes and confidence scores for the first set of predicted 2D bounding boxes,
select, based on the confidence scores for the first set of predicted 2D bounding boxes, a first subset from the first set of predicted 2D bounding boxes,
retrain the model using the image as the input and the first subset as ground truths, wherein the model outputs a second set of predicted 2D bounding boxes and confidence scores for the second set of predicted 2D bounding boxes,
select, based on the confidence scores for the second set of predicted 2D bounding boxes, a second subset of predicted 2D bounding boxes from the second set, and
generate a training set by selecting the 3D bounding boxes from the master set of 3D bounding boxes that have corresponding 2D bounding boxes that form the second subset.
|