| CPC G06V 10/464 (2022.01) [G06F 16/93 (2019.01); G06F 40/20 (2020.01); G06N 20/00 (2019.01); G06V 10/30 (2022.01); G06V 30/413 (2022.01); G06V 30/416 (2022.01)] | 20 Claims |
|
1. An apparatus comprising:
a memory configured to store:
a set of document categories;
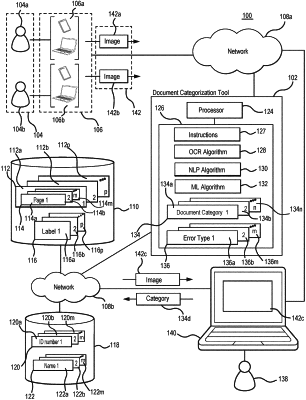
a first set of text generated from a first image of a page of a physical document, the page comprising a second set of text, wherein the first set of text is different from the second set of text by at least a set of errors, the set of errors associated with noise in the first image; and
a machine learning algorithm configured, when applied to the first set of text and executed by a hardware processor, to:
extract a set of features from the first set of text, the set of features comprising:
a first plurality of features obtained by performing natural language processing feature extraction operations on the first set of text; and
a second plurality of features, each feature of the second plurality of features assigned to an error type of a set of error types and associated with one or more errors of the set of errors, the one or more errors belonging to the assigned error type of the set of error types;
generate a first feature vector comprising the first plurality of features and the second plurality of features; and
generate, based on the first feature vector, a first set of probabilities, each probability of the first set of probabilities associated with a document category of the set of document categories and indicating a probability that the physical document from which the first set of text was generated belongs to the associated document category; and
the hardware processor communicatively coupled to the memory, the hardware processor configured to:
apply the machine learning algorithm to the first set of text, to generate the first set of probabilities;
identify a largest probability of the first set of probabilities; and
assign the first image to the document category associated with the largest probability of the first set of probabilities.
|