| CPC G06Q 10/0637 (2013.01) [G06F 18/217 (2023.01); G06F 18/2148 (2023.01); G06F 18/2415 (2023.01); G06F 40/279 (2020.01); G06F 40/49 (2020.01); G06N 5/022 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A method, comprising:
accessing, by a device and utilizing a backend-as-a-service (BaaS) platform application programming interface (API), one or more data sources associated with an organization;
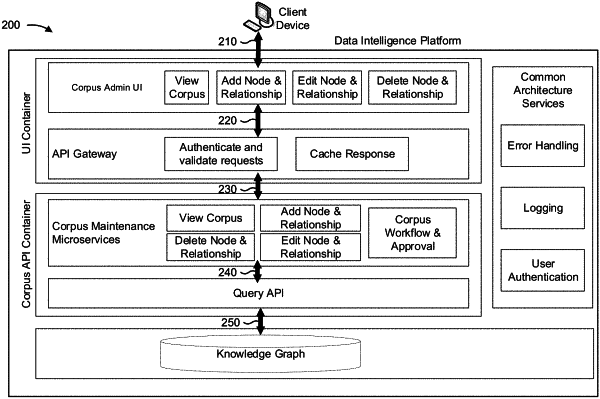
receiving, by the device and utilizing the BaaS platform, data stored in the one or more data sources after accessing the one or more data sources including one or more corpuses associated with the data stored in a knowledge graph;
processing, by the device and utilizing one or more data feature models, the data received from the one or more data sources to identify types of data included in the data based on a contextualization of the data to at least one of:
the organization,
an industry associated with the organization, or
various industries or organizations;
portioning, by the device, a set of data from an enterprise data storage associated with the organization into a training set, a validation set, and a test set;
training, by the device, one or more machine learning models based on the training set;
performing, by the device and after identifying the types of data included in the data, multiple analyses of the data utilizing the one or more corpuses and:
the one or more data feature models, and
the one or more machine learning models,
wherein the one or more corpuses include information that identifies formatting rules associated with the data, value ranges associated with the data, tolerances associated with the data, and expected data elements that are expected to be included in the data,
wherein the multiple analyses include:
a first analysis of a completeness of the data to determine whether data elements are missing from the data based on the expected data elements,
a second analysis of a uniqueness of the data,
a third analysis of an accuracy of the data based on the tolerances and the value ranges, and
a fourth analysis of a validity of the data based on the formatting rules, and
wherein performing the multiple analyses comprises:
performing binary recursive partitioning to split the data into partitions or branches, and
determining, based on the partitions or the branches, results of the multiple analyses; and
performing, by the device, one or more actions based on a respective result of the results of the multiple analyses.
|