| CPC G06F 40/58 (2020.01) [G10L 15/02 (2013.01); G10L 15/063 (2013.01)] | 20 Claims |
|
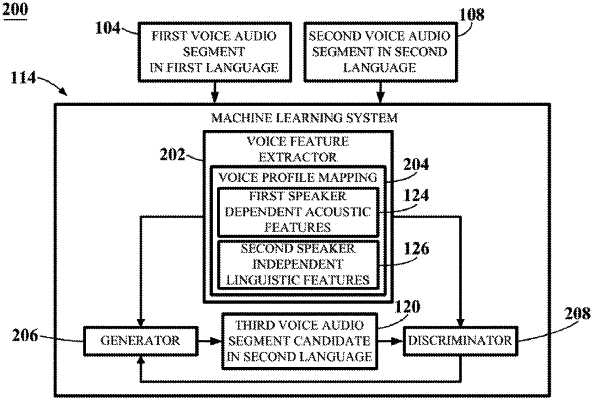
1. A method performed by a machine learning system, the method comprising:
receiving, by a voice feature extractor, a first voice audio segment in a first language and a second voice audio segment in a second language;
extracting, by the voice feature extractor respectively from the first voice audio segment and second voice audio segment, audio features comprising first-voice, speaker-dependent acoustic features and second-voice, speaker-independent linguistic features;
generating, via a generator of a generative adversarial network (GAN) system from a trained data set, a third voice candidate having the first-voice, speaker-dependent acoustic features and the second-voice, speaker-independent linguistic features, wherein the third voice candidate speaks the second language translated based on the first language;
comparing, via one or more discriminators of the GAN system, the third voice candidate with ground truth data comprising the first-voice, speaker-dependent acoustic features and second-voice, speaker-independent linguistic features; and
providing results of the comparing step back to the generator for refining the third voice candidate.
|