| CPC G06F 9/30036 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3013 (2013.01); G06F 17/16 (2013.01)] | 20 Claims |
|
1. A microprocessor system, comprising:
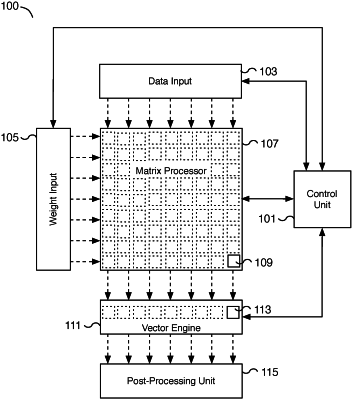
a vector computational unit that includes a plurality of processing elements, wherein each processing element is connected to a corresponding computation unit in a last row of a plurality of computation units included in a computational array,
wherein the computation units are grouped into a plurality of lanes, wherein each lane comprises a subset of the computation units, wherein at least a subset of the plurality of computation units is configured to receive a row of data elements in parallel,
wherein the lanes operate in parallel and shift the row of data elements through the lanes to the vector computational unit, such that information associated with the row of data elements is shifted in parallel through the lanes and the information is provided in parallel from the last row of the computation units to the corresponding processing elements; and
a control unit circuit configured to provide at least a single processor instruction to the vector computational unit, the control unit circuit being configured to synchronize receipt of the data elements from the plurality of lanes to respective processing elements,
wherein the single processor instruction specifies at least three different component instructions to be executed by the vector computational unit in response to the single processor instruction and each of the plurality of processing elements of the vector computational unit is configured to process the received information in response to the single processor instruction.
|