| CPC G06F 8/427 (2013.01) [G06F 8/74 (2013.01); G06N 3/063 (2013.01); G06N 3/10 (2013.01)] | 5 Claims |
|
1. A neural network model conversion method, comprising:
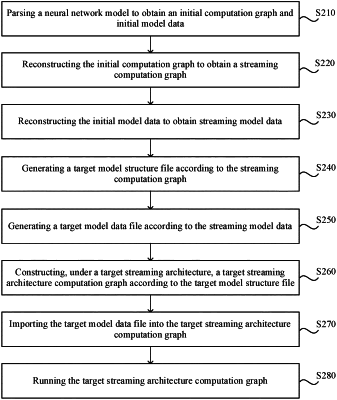
parsing a neural network model to obtain initial model information based on an instruction set architecture chip, the initial model information comprises an initial computation graph and initial model data, the initial computation graph comprises types of first operators and connection relationships among the first operators, and the initial model data comprises corresponding computation parameters of the first operators;
reconstructing the initial model information to obtain streaming model information based on a target streaming architecture chip, the streaming model information comprises a streaming computation graph and streaming model data, the streaming computation graph comprises types of second operators and connection relationships among the second operators, and the streaming model data comprises corresponding computation parameters of the second operators;
generating a target model information file according to the streaming model information, the target model information file is a file that stores neural network model information under the target streaming architecture chip;
generating a target model structure file according to the streaming computation graph, and generating a target model data file according to the streaming model data; and
in the target streaming architecture chip, constructing a target streaming architecture computation graph according to the target model structure file, importing the target model data file into the target streaming architecture computation graph; and running the target streaming architecture computation graph.
|