| CPC G10L 19/00 (2013.01) [G06F 40/126 (2020.01); G06N 3/045 (2023.01); G10L 15/00 (2013.01)] | 20 Claims |
|
1. A system comprising:
a memory that stores computer executable components;
a processor that executes at least one of the computer executable components that:
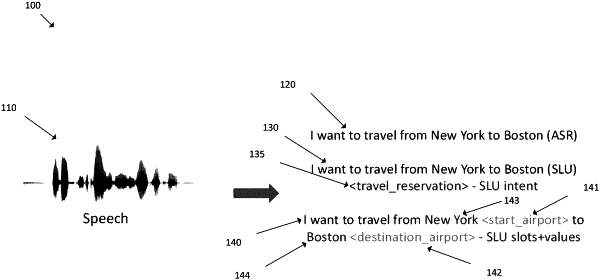
trains a hierarchical conversational neural network model to generate spoken language understandings directly of speech dialogs in an audio modality without converting the speech dialogs to a text modality, wherein the training comprises:
encoding, using a text encoder of the hierarchical conversational neural network model, utterances of a training speech dialog in the audio modality, converted into the text modality, into first embeddings in a uniform embedding representation;
encoding, using a speech encoder of the hierarchical conversational neural network model, the utterances of the training speech dialog in the audio modality, without being converted into the text modality, into second embeddings in the uniform embedding representation; and
training, using the first embeddings of the utterances in the text modality and the second embeddings of the utterances in the audio modality, a conversation encoder of the hierarchical conversational neural network model to generate a spoken language understanding of the training speech dialog in the audio modality without converting the training speech dialog to the text modality.
|