| CPC G06V 10/82 (2022.01) [G06F 18/22 (2023.01); G06N 20/00 (2019.01); G06V 20/20 (2022.01); G06V 20/41 (2022.01); G06V 30/19173 (2022.01); G06V 30/274 (2022.01); G06V 40/10 (2022.01); G06V 40/113 (2022.01); G06V 40/28 (2022.01); G09B 5/065 (2013.01); G09B 19/003 (2013.01); G10L 15/1815 (2013.01); G10L 25/57 (2013.01)] | 20 Claims |
|
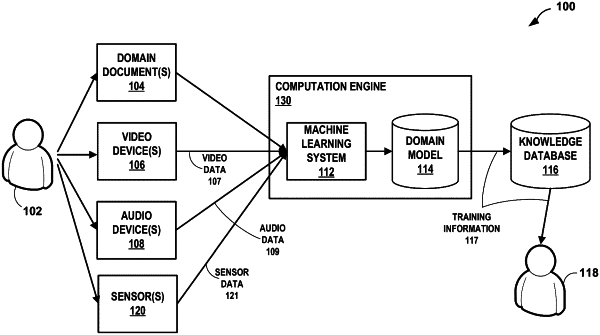
1. A system for capturing knowledge for performing a task, the system comprising:
a domain model defining a plurality of steps for performing the task;
a video input device configured to obtain video data of a first user performing the plurality of steps for performing the task;
an audio input device configured to obtain audio data describing performance of the plurality of steps for performing the task;
one or more sensors configured to generate sensor data during performance of the plurality of steps for performing the task;
a computation engine configured to:
correlate at least two of the video data, the audio data, and the sensor data to identify at least a portion of each of the at least two of the video data, the audio data, and the sensor data that depicts a same step of the plurality of steps; and
process the identified at least a portion of each of the at least two of the video data, the audio data, and the sensor data to update the domain model defining the plurality of steps for performing the task;
a training unit configured to apply the updated domain model to generate training information for performing the plurality of steps for performing the task; and
an output device configured to output the training information for use in training a second user to perform the plurality of steps for performing the task.
|