| CPC G06F 40/40 (2020.01) [G10L 13/08 (2013.01)] | 14 Claims |
|
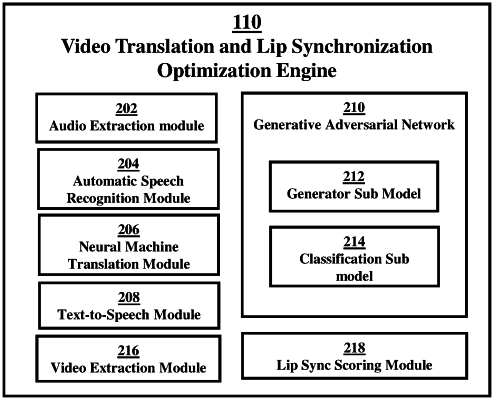
1. A computer-implemented method for optimizing generated lip-synced videos for neural machine translations, the computer-implemented method comprising:
receiving, by a processor, a source video of a speaker in a source language;
synthesizing a plurality of speech translations of the source video in a target language, where the target language is different than the source language, based on a neural machine translation model, wherein the neural machine translation model is trained to synthesize a variable number of translations based on a variable beam width, wherein synthesizing comprises: extracting audio data from the source video, generating a transcript in the source language for the extracted audio data; generating at least one translation script in the target language based on the transcript in the source language, wherein the number of translation scripts is based on the variable beam width; and converting each translation script into speech based on a text to speech system, wherein the translation script is the topK result of the translation into the target language;
generating a lip synchronized video for each of the plurality of synthesized speech translations based on a generation sub-model within a generative adversarial network architecture;
classifying each lip synchronized video as synchronized or not synchronized, based on a classification sub-model within a generative adversarial network; and
generating a lip-sync score for each lip synchronized video classified as synchronized.
|