| CPC G06F 40/268 (2020.01) [G06F 40/232 (2020.01); G06F 40/30 (2020.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01)] | 9 Claims |
|
1. A difference extraction device comprising processing circuitry configured to:
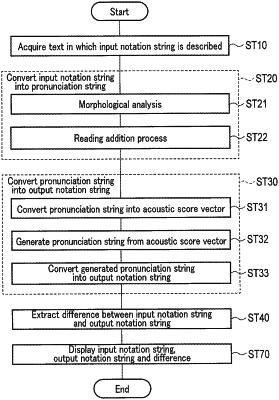
acquire a text in which an input notation string is described;
convert the input notation string into a pronunciation string;
convert the pronunciation string into an output notation string;
extract a difference by comparing the input notation string and the output notation string with each other, and determining, as the difference, based on a result of the comparison, a part of the output notation string which differs from a part of the input notation string, wherein said parts are respectively located at corresponding positions in the input notation string and the output notation string;
analyze the input notation string;
estimate a notation of a word candidate contained in the input notation string and including the difference, based on an analysis result of the input notation string; and
determine a word type of the word candidate,
wherein:
where the notation of the word candidate is estimated, the processing circuitry extracts, from the input notation string, a character string estimated to form a word by concatenating the difference and at least one character adjacent to the difference, and outputs the extracted character string as the estimated notation of the word candidate,
where the word type of the word candidate is determined, the processing circuitry determines, using a different notation dictionary which is a dictionary listing different notations of a same word with a same meaning, if two notations including the notation of the word candidate and the notation in the output notation string corresponding to the notation of the word candidate are present in the different notation dictionary, that the two notations are caused by a notation fluctuation,
where the pronunciation string is converted into the output notation string,
the processing circuitry is further configured to:
convert the pronunciation string into an acoustic score vector;
store a language model and a word dictionary for speech recognition in a memory; and
generate a second pronunciation string from the acoustic score vector and convert the generated second pronunciation string into the output notation string, using the language model and the word dictionary,
wherein the acoustic score vector is a 102-dimensional vector representing a likelihood of each of syllables included in the pronunciation string that is in a Japanese language, a pronunciation of each of the syllables being expressed by a single state, the Japanese language including 102 syllables, and
wherein the processing circuitry is further configured to execute a display control process in which the input notation string including the word candidate is displayed on a display and in which the notation of the word candidate is displayed on the display, using a display attribute based on the word candidate.
|