| CPC G06F 3/167 (2013.01) [G06F 3/00 (2013.01); G06F 3/005 (2013.01); G06F 3/01 (2013.01); G06F 3/011 (2013.01); G06F 3/16 (2013.01); G06F 18/20 (2023.01); G06V 40/171 (2022.01); G10L 17/18 (2013.01); G10L 17/22 (2013.01)] | 20 Claims |
|
1. An electronic device comprising:
a microphone comprising circuitry;
a communication interface;
a speaker comprising circuitry; and
a processor electrically connected to the microphone, the communication interface and the speaker,
wherein the processor is configured to:
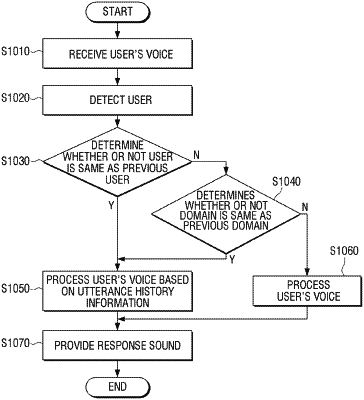
based on a first user's voice being input via the microphone, identify a user who uttered the first user's voice,
control the communication interface to transmit the first user's voice to a server, and receive a first response sound from the server through the communication interface,
provide the first response sound via the speaker,
based on a second user's voice being input via the microphone, identify a user who uttered the second user's voice,
based on the user who uttered the first user's voice being the same as the user who uttered the second user's voice, control the communication interface to transmit the second user's voice and utterance history information to the server, and receive a second response sound from the server through the communication interface, and
provide the second response sound via the speaker,
wherein the server is configured to obtain the first response sound by inputting the first user's voice to an artificial intelligence model trained through an artificial intelligence algorithm, and the second response sound by inputting the second user's voice and the utterance history information to the artificial intelligence model, and
wherein the utterance history information comprises user's voice including the first user's voice and a response sound including the first response sound.
|