| CPC G06F 17/16 (2013.01) | 20 Claims |
|
1. A computing device comprising:
a hardware accelerator including an on-chip controller configured to control the hardware accelerator to:
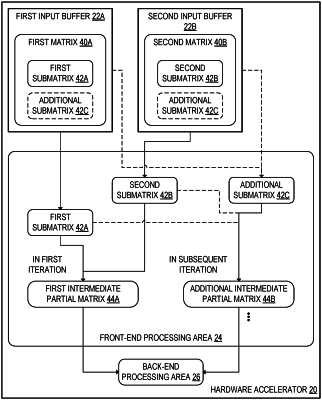
receive a first matrix at a first input buffer;
receive a second matrix at a second input buffer;
for a plurality of partial matrix regions each including a plurality of partial matrices:
in a first iteration of a plurality of iterations:
read, into a front-end processing area included in the hardware accelerator and operatively coupled to the first input buffer and the second input buffer, a first submatrix of the first matrix and a second submatrix of the second matrix; and
at the front-end processing area, multiply the first submatrix by the second submatrix to compute a first intermediate partial matrix of a plurality of intermediate partial matrices;
in each of one or more subsequent iterations of the plurality of iterations:
read an additional submatrix into the front-end processing area; and
at the front-end processing area, compute an additional intermediate partial matrix of the plurality of intermediate partial matrices as a product of the additional submatrix and a submatrix reused from an immediately prior iteration of the plurality of iterations, wherein the hardware accelerator is configured to alternate between reusing respective submatrices of the first matrix and the second matrix;
at a back-end processing area included in the hardware accelerator and operatively coupled to the front-end processing area, compute each partial matrix of the plurality of partial matrices as a sum of two or more of the intermediate partial matrices that correspond to a shared position within the partial matrix region; and
output the plurality of partial matrices to one or more other components of the computing device via a result buffer.
|