| CPC G06F 15/8069 (2013.01) [G06F 9/30163 (2013.01); G06F 9/3877 (2013.01); G06T 15/005 (2013.01); G06F 9/3836 (2013.01)] | 18 Claims |
|
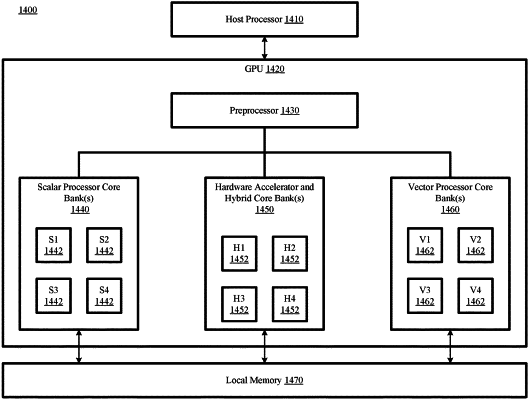
1. An apparatus comprising:
a scalar processor complex comprising a plurality of scalar processor cores;
a vector processor complex comprising a plurality of vector processor cores;
a hardware accelerator bank comprising a tensor core to perform matrix processing for deep learning operations using a plurality of operand precisions; and
a pre-processor communicably coupled to the scalar processor complex, the vector processor complex, and the hardware accelerator bank, wherein the pre-processor to:
receive a binary translation of a code segment of a plurality of code segments corresponding to a set of workload instructions for a graphics workload from a host processor;
analyze operations of the binary translation to identify whether the operations are suitable for execution by one of the scalar processor complex, the vector processor complex, or the hardware accelerator bank; and
assign, to the scalar processor complex, the operations of the binary translation that are identified as suitable for execution by the scalar processor complex.
|