| CPC A61B 1/000094 (2022.02) [A61B 1/000096 (2022.02); A61B 1/0005 (2013.01); A61B 1/05 (2013.01); A61B 1/0655 (2022.02); A61B 8/4245 (2013.01); A61B 8/463 (2013.01); A61B 8/469 (2013.01); G06T 7/0012 (2013.01); G06T 2207/10068 (2013.01); G06T 2207/10132 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30096 (2013.01)] | 18 Claims |
|
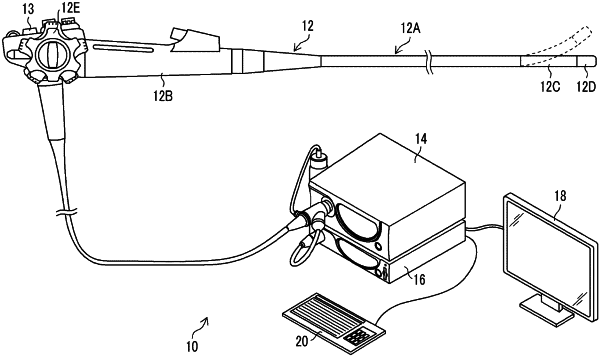
1. An endoscope system comprising:
an endoscope configured to be inserted into a body cavity of a subject; and one or more processors configured to:
acquire images at in-vivo positions of the subject by sequentially capturing the images through the endoscope;
acquire positional information indicating the in-vivo positions of the acquired images;
select a learned model that is a model learned using images corresponding to a position indicated by the acquired positional information among a plurality of learned models that are models learned using data sets including images at different in-vivo positions respectively and are configured to detect a region of interest;
cause the selected learned model to detect a region of interest in the acquired images;
and cause a display to display the position indicated by the acquired positional information, wherein-the learned models are models learned using data sets including images of mucous membranes at different in-vivo positions, respectively.
|