| CPC G06F 18/211 (2023.01) [G06F 18/40 (2023.01); G06N 20/00 (2019.01)] | 10 Claims |
|
1. A computer-implemented method, the method comprising:
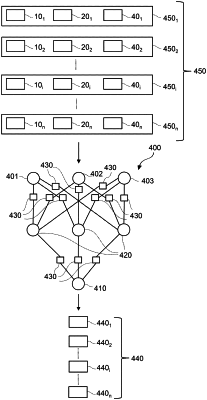
receiving a plurality of data records from a plurality of networked entities, wherein each data record comprises a value corresponding to a first feature, a value corresponding to a second feature, and a target value;
selecting either the first feature or the second feature as a selected feature;
updating each data record with a generated further feature, wherein the further feature is calculated as either: a weighted ratio of the first feature to the second feature, or a logarithmic function of the first feature;
calculating a first correlation metric as a measure of a correlation between the selected feature and the further feature;
training a machine learning module (ML-module) until a training error is below a training error threshold, wherein the training comprises repeatedly:
inputting each updated data record as training data to the ML-module, resulting in a respective change of a value of each model parameter, a training error, and training output values, each training output value corresponding to each input further feature;
sorting the values of the generated further feature in ascending order, and dividing the sorted values of the generated further feature into a first subset dataset and a second subset dataset;
determining a bias metric indicating a strength of a bias of the ML-module toward the first subset dataset or the second subset dataset, based on the correlation metric being greater than a threshold; and
releasing the ML-module for usage if the determined bias metric satisfies a bias constraint, wherein the releasing comprises storing the model parameters and structural parameters of the ML-module, storing the correlation metrics, and bias metrics in a form of meta data of the ML-module.
|