| CPC G06F 3/0616 (2013.01) [G06F 3/0652 (2013.01); G06F 3/0653 (2013.01); G06F 3/0673 (2013.01)] | 16 Claims |
|
1. A data storage device comprising:
a memory; and
a processor coupled with the memory and configured to:
identify a plurality of blocks in the memory that may require a read scrub operation by tracking age and read count of each block of the plurality of blocks, wherein age and read count of a block are directly proportional to a likelihood of data retention errors and read disturb errors, respectively, in the block, and wherein each block in the plurality of blocks is identified by:
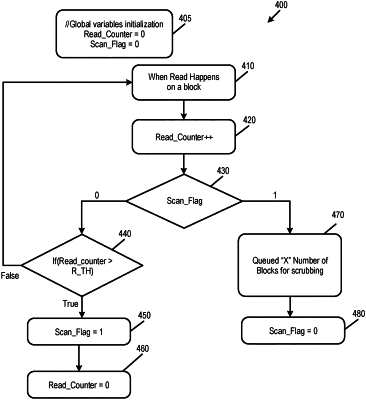
incrementing a read counter when the block is read;
determining whether a scan flag is set;
in response to determining that the scan flag is not set:
determining if the read counter for the block is greater than a read threshold; and
in response to determining that the read counter for the block is greater than the read threshold:
set the scan flag; and
reset the read counter for the block; and
in response to determining that the read counter for the block is not greater than the read threshold, continue tracking reads on the block; and
in response to determining that the scan flag is set:
queue the block for scrubbing; and
reset the scan flag;
train a machine learning Y(X1,X2) model, wherein Y is a target variable that designates a number of bit-flips for a block, X1 is a dependent variable that designates a number of reads done on a block since a block was opened for programming, and X2 is a dependent variable that designates an age of a block;
use the machine learning Y(X1,X2) model to estimate a number of bit-flips in each of the plurality blocks based on the tracked ages and read counts of each of the plurality of blocks, wherein the ages are tracked based on time stamps created when each of the plurality of blocks was opened;
determine whether the machine learning Y(X1,X2) model needs to be refreshed;
in response to determining that the machine learning Y(X1,X2) model does not need to be refreshed, identify a subset of the plurality of blocks that have an estimated number of bit-flips above a threshold;
in response to determining that the machine learning Y(X1,X2) model needs to be refreshed, refresh the machine learning Y(X1,X2) model before identifying the subset of the plurality of blocks that have the estimated number of bit-flips above the threshold, wherein the machine learning Y(X1,X2) model is refreshed using offline error characterization data or using run-time data samples collected when a scan happens; and
improve a scan-hit-rate by:
instead of scanning all of the plurality of blocks, scanning only the subset of the plurality of blocks to determine which blocks of the subset of the plurality of blocks require the read scrub operation; and
performing the read scrub operation only on the blocks of the subset of the plurality of blocks that are determined to require the read scrub operation;
wherein the scan-hit-rate is improved by reducing a number of blocks that are scanned to find the blocks that require the read scrub operation.
|