| CPC H04N 21/4884 (2013.01) [G06F 40/30 (2020.01); G06F 40/58 (2020.01); H04N 21/43074 (2020.08)] | 20 Claims |
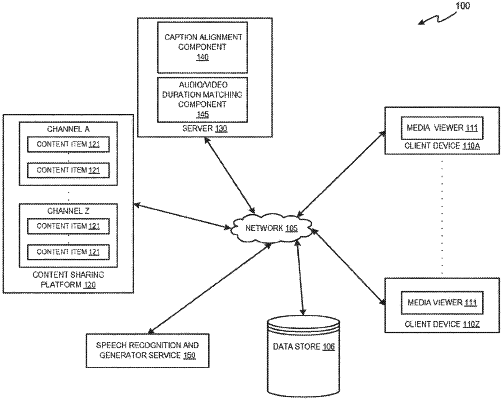
|
1. A method comprising:
identifying, by a processing device, original caption data for a video having audio that includes speech recorded in an original language, wherein the original caption data comprises a plurality of caption character strings in the original language and associated with audio portion of the video;
identifying, by the processing device, translated language caption data for the video, wherein the translated language caption data comprises a plurality of translated character strings associated with the audio portion of the video;
generating, by the processing device, a set of caption sentence fragments from the plurality of caption character strings and a set of translated sentence fragments from the plurality of translated character strings;
mapping, by the processing device, caption sentence fragments of the set of caption sentence fragments to corresponding translated sentence fragments of the set of translated sentence fragments based on timing associated with the original caption data and the translated language caption data;
estimating, by the processing device, time intervals for individual caption sentence fragments of the set of caption sentence fragments using timing information corresponding to individual caption character strings;
assigning, by the processing device, time intervals to individual translated sentence fragments of the set of translated sentence fragments based on estimated time intervals of the individual caption sentence fragments;
generating, by the processing device, a set of translated sentences using consecutive translated sentence fragments of the set of translated sentence fragments; and
aligning, by the processing device, the set of translated sentences with the audio portion of the video using assigned time intervals of individual translated sentence fragments from corresponding translated sentences.
|