| CPC H04L 43/16 (2013.01) [G06F 3/0619 (2013.01); H04L 41/0893 (2013.01); H04L 41/149 (2022.05); H04L 43/0817 (2013.01)] | 20 Claims |
|
1. A system for monitoring network processing using node analysis in a communication network, in real time, wherein the system is structured for precluding outages of network components from causing the system to be taken offline, based on structuring network nodes into clusters and analyzing node commands and node operations, the system comprising:
a plurality of network nodes, wherein each of the plurality of network nodes is associated with an individual server of the communication network;
at least one data collector agent component, wherein each of the plurality of network nodes is connected to the data collector agent component, wherein the data collector agent component is structured to receive node operation information from the plurality of network nodes;
an application protection engine component operatively connected to the data collector agent component, wherein the application protection engine component is structured to receive (i) live input feeds and (ii) application alerts from the data collector agent component, and analyze and approve node commands associated with the plurality of network nodes;
an application protection engine data repository;
at least one non-transitory storage device; and
at least one processing device coupled to the at least one non-transitory storage device, wherein the at least one processing device is configured to:
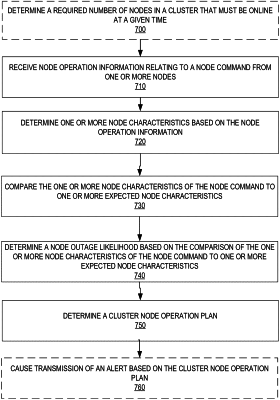
receive, via the at least one data collector agent component, the node operation information relating to a node command from one or more nodes of the plurality of network nodes, wherein the one or more nodes are grouped into a cluster in which a required number of nodes must be online at a given time, wherein the node command comprises server boot, server reboot, remote execution, and defined application operations;
deny execution of the node command until approval of the node command by the application protection engine component;
transmit, via the at least one data collector agent component, the node command to the application protection engine component;
based on the node operation information, determine one or more node characteristics, wherein the node characteristics relate to one or more operating indicators and health indicators of a given node, wherein the health indicators of the given node are continuously monitored;
compare the one or more node characteristics of the node command to one or more expected node characteristics, wherein the expected node characteristics are extracted from the application protection engine data repository and are based on same or similar node commands previously executed, comprising determining a failing node in response to determining a deviation from the previously executed node commands;
based on comparing the one or more node characteristics of the node command to one or more expected node characteristics, determine a node outage likelihood, wherein the node outage likelihood indicates likelihood the given node will experience a node outage within a predetermined amount of time and a duration of the node outage for which the given node will be inoperable;
determine a cluster node operation plan, wherein the cluster node operation plan is configured to determine the nodes of the cluster that must be in operation in an event of the node outage of the given node, wherein determining the cluster node operation plan further comprises:
detecting planned node outages associated with the one or mode nodes; and
modifying, in response to the node outage likelihood, the planned node outages associated with the one or mode nodes, such that the inoperability of the cluster is precluded;
transmit a notification of the node outage likelihood indicating a replace or repair requirement for the given node; and
implement an expected node outage solution for the event of the node outage of the given node.
|