| CPC G10L 17/16 (2013.01) [G10L 17/02 (2013.01); G10L 17/06 (2013.01); G10L 17/18 (2013.01); G10L 21/028 (2013.01)] | 17 Claims |
|
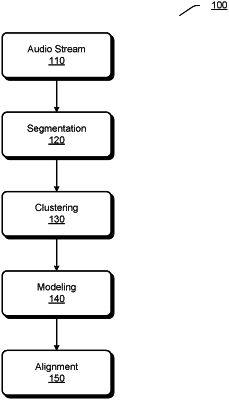
1. A method for speaker diarization, the method comprising:
segmenting an audio stream into at least one speech segment, the audio stream comprising speeches from at least one speaker;
initializing a dataset by the at least one speech segment, the dataset comprising at least one data item initialized by the at least one speech segment respectively;
iteratively clustering the at least one data item into a plurality of clusters based on cosine similarity and Bayesian Information Criterion (BIC) scores among data items in the dataset, the number of the plurality of clusters being greater than the number of the at least one speaker;
selecting, from the plurality of clusters, at least one cluster of the highest similarity, the number of the selected at least one cluster being equal to the number of the at least one speaker, wherein said selecting is performed by:
calculating a similarity matrix of the plurality of clusters;
exhaustively extracting a plurality of similarity sub-matrices from the similarity matrix, each similarity sub-matrix being a M
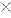 M matrix, M being the number of the at least one speaker; M matrix, M being the number of the at least one speaker;calculating an eigen vector of each similarity sub-matrix;
obtaining an eigenvalue summation of each similarity sub-matrix through summating eigenvalues in an eigen vector of the similarity sub-matrix;
identifying a similarity sub-matrix having the maximum eigenvalue summation from the plurality of similarity sub-matrices; and
selecting a group of M clusters corresponding to the identified similarity sub-matrix;
establishing a speaker classification model based on the selected at least one cluster; and
aligning, through the speaker classification model, speech frames in the audio stream to the at least one speaker.
|