| CPC G10L 15/22 (2013.01) [G10L 15/01 (2013.01); G10L 15/063 (2013.01); G10L 15/08 (2013.01); G10L 2015/0631 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
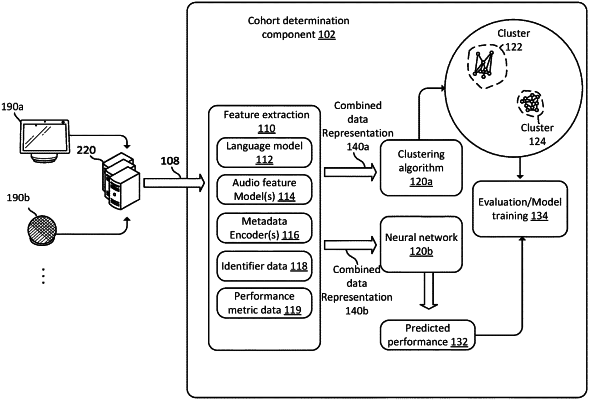
1. A computer-implemented method comprising:
determining a first account identifier associated with a natural language processing system;
receiving a natural language input associated with the first account identifier over a first past time period;
generating, using a language model, first data representing the natural language input;
receiving first audio data representing the natural language input;
generating, using an acoustic model, second data representing the first audio data;
determining third data representing a performance metric of the natural language processing system, the performance metric associated with predicted error during processing of the natural language input;
generating fourth data by concatenating at least the first data, the second data, and the third data;
generating, using an unsupervised clustering algorithm, a plurality of clusters of account identifiers, wherein a first cluster of the plurality of clusters includes the fourth data and a plurality of other data representations;
determining an average score of the performance metric for the first cluster;
determining that the average score of the performance metric is associated with underperformance of the natural language processing system for the natural language input;
generating a training data set for a first machine learning model of the natural language processing system, the training data set including the fourth data and the plurality of other data representations; and
generating updated parameters of the first machine learning model using the training data set.
|
|
4. A method comprising:
receiving a first natural language input to a natural language processing system, the first natural language input being associated with a first account identifier;
determining, using a first machine learning model, first data representing one or more words of the first natural language input;
determining, using a second machine learning model, second data representing one or more acoustic characteristics of the first natural language input;
determining, based at least in part on the first data and the second data, third data representing a predicted performance for processing the first natural language input by the natural language processing system; and
determining, based at least in part on the predicted performance, a first cluster associated with the first natural language input, wherein the first cluster comprises data representing past natural language inputs.
|
|
13. A system comprising:
at least one processor; and
non-transitory computer-readable memory storing instructions that, when executed by the at least one processor, are effective to:
receive a first natural language input to a natural language processing system, the first natural language input being associated with a first account identifier;
determine, using a first machine learning model, first data representing one or more words of the first natural language input;
determine, using a second machine learning model, second data representing one or more acoustic characteristics of the first natural language input;
determine, based at least in part on the first data and the second data, third data representing a predicted performance for processing the first natural language input by the natural language processing system; and
determine, based at least in part on the predicted performance a first cluster associated with the first natural language input, wherein the first cluster comprises data representing past natural language inputs.
|