| CPC G10L 15/22 (2013.01) [G06F 40/117 (2020.01); G06F 40/253 (2020.01); G06F 40/30 (2020.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/1815 (2013.01)] | 20 Claims |
|
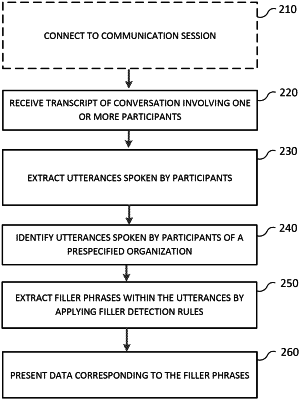
1. A method, comprising:
receiving a transcript of a conversation involving one or more participants produced during a communication session within a communication platform;
extracting, from the transcript, a plurality of utterances comprising one or more sentences spoken by the participants, wherein each utterance of the plurality of utterances is associated with a topic of discussion for a portion of the communication session corresponding to the utterance;
identifying a subset of the plurality of utterances spoken by a subset of the participants associated with a prespecified organization;
extracting one or more filler phrases within the subset of utterances, the filler phrases each comprising one or more words representing disfluencies within a sentence, extracting the one or more filler phrases comprising:
applying one or more filler detection rules to the subset of utterances to detect the filler phrases and classify the filler phrases into filler types from a predetermined list of filler types;
correlating each filler phrase of the one or more filler phrases with the corresponding topic of discussion and a participant of the subset of the participants that spoke the filler phrase;
aggregating the filler phrases for multiple participants across multiple communication sessions; and
presenting, for display to one or more users of the communication platform, data corresponding to the aggregated filler phrases for each participant of the subset of the participants associated with the prespecified organization.
|