| CPC G10L 15/20 (2013.01) [G01S 13/88 (2013.01); G10L 15/063 (2013.01); G10L 15/1815 (2013.01); G10L 15/22 (2013.01); G10L 15/28 (2013.01); G10L 25/18 (2013.01); G10L 25/78 (2013.01)] | 14 Claims |
|
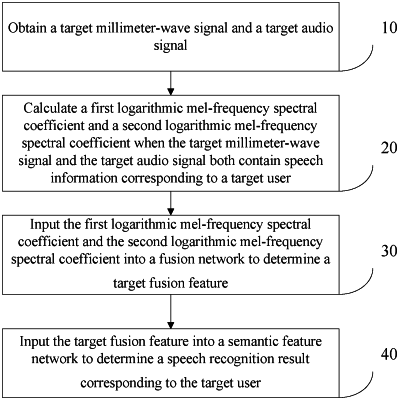
1. A multimodal speech recognition method, comprising:
obtaining a target millimeter-wave signal and a target audio signal;
calculating a first logarithmic mel-frequency spectral coefficient and a second logarithmic mel-frequency spectral coefficient when the target millimeter-wave signal and the target audio signal both contain speech information corresponding to a target user, wherein the first logarithmic mel-frequency spectral coefficient is determined based on the target millimeter-wave signal, and the second logarithmic mel-frequency spectral coefficient is determined based on the target audio signal;
inputting the first logarithmic mel-frequency spectral coefficient and the second logarithmic mel-frequency spectral coefficient into a fusion network to determine a target fusion feature, wherein the fusion network comprises at least a calibration module and a mapping module; the calibration module is configured to perform feature calibration on the target millimeter-wave signal based on the target audio signal to obtain a calibrated millimeter-wave feature and perform feature calibration on the target audio signal based on the target millimeter-wave signal to obtain a calibrated audio feature; and the mapping module is configured to fuse the calibrated millimeter-wave feature and the calibrated audio feature to obtain the target fusion feature; and
inputting the target fusion feature into a semantic feature network to determine a speech recognition result corresponding to the target user,
wherein the fusion network further comprises two identical branch networks including a first branch network and a second branch network; and each branch network comprises a first residual block with efficient channel attention (ResECA), a second ResECA, a third ResECA, a fourth ResECA, and a fifth ResECA; wherein
an input end of the calibration module is respectively connected to an output end of the third ResECA of the first branch network and an output end of the third ResECA of the second branch network; and an output end of the calibration module is respectively connected to an input end of the fourth ResECA of the first branch network and an input end of the fourth ResECA of the second branch network;
an input end of the first ResECA of the first branch network is used to input the first logarithmic mel-frequency spectral coefficient; and an output end of the first ResECA of the first branch network is connected to an input end of the second ResECA of the first branch network, an output end of the second ResECA of the first branch network is connected to an input end of the third ResECA of the first branch network, and an output end of the fourth ResECA of the first branch network is connected to an input end of the fifth ResECA of the first branch network;
an input end of the first ResECA of the second branch network is used to input the second logarithmic mel-frequency spectral coefficient; and an output end of the first ResECA of the second branch network is connected to an input end of the second ResECA of the second branch network, an output end of the second ResECA of the second branch network is connected to an input end of the third ResECA of the second branch network, and an output end of the fourth ResECA of the second branch network is connected to an input end of the fifth ResECA of the second branch network; and
an input end of the mapping module is respectively connected to an output end of the fifth ResECA of the first branch network and an output end of the fifth ResECA of the second branch network.
|