| CPC G10L 15/063 (2013.01) [G10L 15/14 (2013.01); G10L 21/02 (2013.01)] | 18 Claims |
|
8. A computer program product residing on a non-transitory computer readable medium having a plurality of instructions stored thereon which, when executed by a processor, cause the processor to perform operations comprising:
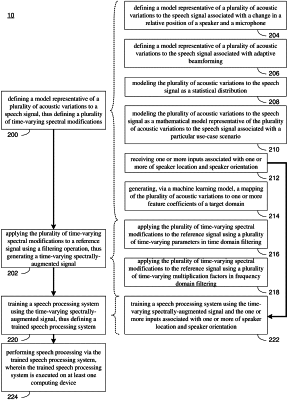
defining a model representative of a plurality of acoustic variations to a speech signal associated with an adaptive beamforming, thus defining a plurality of time-varying spectral modifications, wherein the plurality of acoustic variations to the speech signal include frequency-based variations in a speech signal beampattern from a movement of a plurality of beampatterns formed by a microphone array configured for the adaptive beamforming and a beamsteering by dynamically modifying and steering the plurality of beampatterns toward a speaker; and
applying the plurality of time-varying spectral modifications to a plurality of feature coefficients of a target domain of a reference signal using a filtering operation, thus generating a plurality of time-varying spectrally-augmented feature coefficients of the reference signal,
wherein applying the plurality of time-varying spectral modifications to the plurality of feature coefficients of the target domain of the reference signal includes:
generating, via a machine learning model, a mapping of the plurality of acoustic variations to one or more feature coefficients of the target domain representative of the frequency-based variations in the speech signal beampattern from the model representative of the plurality of acoustic variations,
applying, via the machine learning model, the mapping of the plurality of acoustic variations to the plurality of feature coefficients of the reference signal, and
generating, via the machine learning model, augmented data from the reference signal and one or more parameters associated with a particular acoustic variation of the plurality of acoustic variations.
|