| CPC G06V 20/41 (2022.01) [G06N 20/00 (2019.01); G06V 20/46 (2022.01); G06V 20/49 (2022.01)] | 16 Claims |
|
1. A computer-implemented method for classifying video data with improved accuracy, the method comprising:
obtaining, by a computing system comprising one or more computing devices, video data comprising a plurality of video frames;
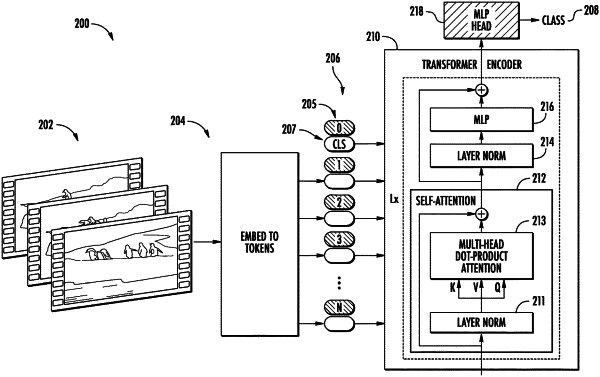
extracting, by the computing system, a plurality of video tokens from the video data, the plurality of video tokens comprising a representation of spatiotemporal information in the video data,
wherein extracting the plurality of video tokens from the video data comprises:
extracting, by the computing system, a plurality of video tubelets from the video data, the plurality of video tublets respectively comprising a length and a width and spanning two or more video frames of the plurality of video frames;
projecting, by the computing system, the plurality of video tubelets to a plurality of tensor representations of the plurality of video tubelets; and
merging, by the computing system, the plurality of tensor representations along at least one dimension to produce the plurality of video tokens;
providing, by the computing system, the plurality of video tokens as input to a video understanding model, the video understanding model comprising a video transformer encoder model; and
receiving, by the computing system, a classification output from the video understanding model.
|