| CPC G06T 7/55 (2017.01) [B25J 9/1605 (2013.01); B25J 9/163 (2013.01); B25J 9/1669 (2013.01); B25J 9/1697 (2013.01); B25J 13/08 (2013.01); G06F 18/2163 (2023.01); G06T 7/50 (2017.01); G06V 20/10 (2022.01); G06V 20/64 (2022.01); G06T 2207/10024 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/20132 (2013.01)] | 18 Claims |
|
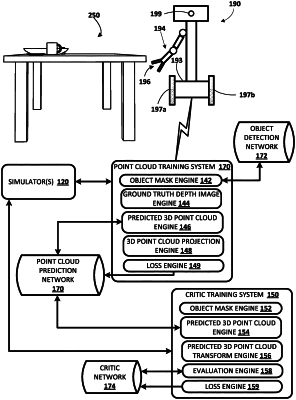
1. A method implemented by one or more processors of a robot, the method comprising:
identifying an image captured by a camera of the robot, the image capturing an object to be manipulated by the robot, and the image comprising multiple channels, including one or more color channels and a depth channel;
generating an object mask of the object to be manipulated by the robot, wherein generating the object mask comprises:
processing one or more of the channels of the image using an object detection network;
generating a three-dimensional (3D) point cloud of the object, wherein generating the 3D point cloud of the object comprises:
processing, using a point cloud prediction network:
all of the channels of at least a portion of the image, and
the generated object mask of the object;
generating a prediction of successful manipulation of the object, wherein generating the prediction of successful manipulation of the object comprises:
generating the prediction of successful manipulation by processing a transformation of the 3D point cloud, using a robotic manipulation policy model,
wherein generating the prediction of successful manipulation comprises:
sampling, from multiple candidate end effector poses, a candidate end effector pose, of an end effector of the robot,
generating the transformation of the 3D point cloud by transforming the 3D point cloud to an end effector frame that is relative to the candidate end effector pose, and
generating the prediction of successful manipulation by processing the transformation of the 3D point cloud using the robotic manipulation policy model; and
controlling one or more actuators of the robot based on the prediction of successful manipulation.
|