| CPC G06T 1/20 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3017 (2013.01); G06F 9/3851 (2013.01); G06F 9/3887 (2013.01); G06F 9/3895 (2013.01); G06N 3/04 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01)] | 20 Claims |
|
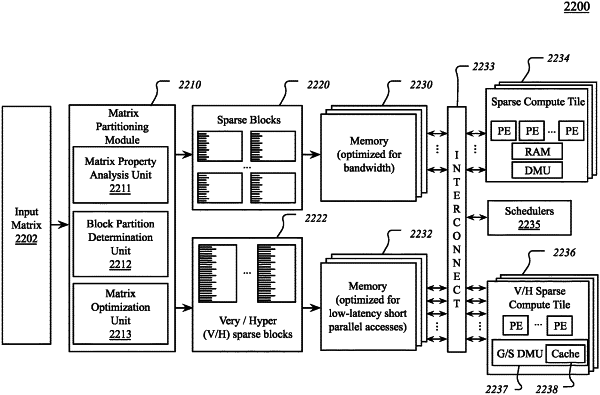
1. A parallel processor comprising:
a hardware scheduler to schedule pipeline commands for compute operations to one or more of multiple types of compute units, wherein the multiple types of compute units include a first sparse compute unit configured for input at a first level of sparsity and a second sparse compute unit configured for input at a second level of sparsity that is greater than the first level of sparsity;
a plurality of processing resources coupled with the hardware scheduler, the plurality of processing resources including the first sparse compute unit; and
hybrid memory circuitry coupled with the plurality of processing resources, the hybrid memory circuitry including a memory controller, a memory interface, and the second sparse compute unit.
|