| CPC G06Q 20/4016 (2013.01) [G06N 5/01 (2023.01); G06N 5/046 (2013.01); G06N 20/00 (2019.01)] | 17 Claims |
|
1. A system for providing rule-based machine learning for precise fraud detection in heavily imbalanced datasets, the system comprising:
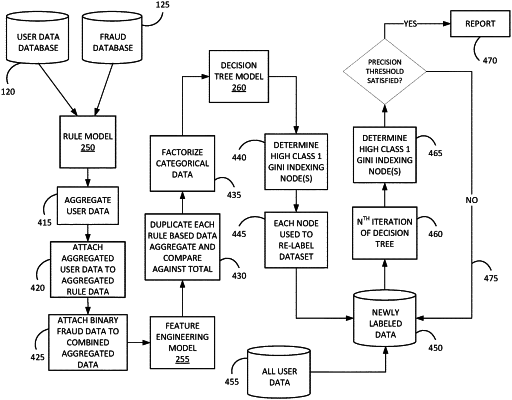
a server including an electronic processor, a memory, and an electronic communication interface, wherein the memory stores software modules including a rule-based model, a feature engineering model, and a decision tree model, wherein the electronic communication interface is configured to be in electronic communication with a plurality of user computing devices conducting transaction interactions with the server;
the electronic processor configured to
receive, from a user data database via the electronic communication interface, a first collection of datasets associated with user interaction data, wherein each dataset included in the first collection of datasets is associated with one or more user characteristics,
receive, from a fraud database via the electronic communication interface, a second collection of datasets associated with user interaction data,
generate, using the rule-based model, an aggregate dataset collection based on the first collection of datasets and the second collection of datasets, wherein each dataset in the aggregate dataset collection is labeled with a binary target variable indicating whether a user characteristic of each dataset is associated with fraud, wherein the user characteristic comprises at least one datapoint in each dataset which represents a count of the number of times the user has interacted with the server in a single electronic transaction interaction or session,
supplement, using the feature engineering model, the aggregate dataset collection by converting the at least one datapoint included in each dataset of the aggregate dataset collection from a count value to a percentage value, wherein the percentage value is added as a new datapoint for each dataset included in the aggregate dataset collection,
determine, via a first iteration of the decision tree model, a first subset of datasets of the aggregate dataset collection, wherein each dataset included in the first subset of datasets is associated with a first set of user characteristics associated with fraud, wherein the determining is based on an accuracy score generated by a precision metric,
relabel, based on the first set of user characteristics, each dataset included in the first subset of datasets with a new binary target variable indicating whether each dataset included in the first subset of datasets is associated with fraud,
generate, by excluding the datasets not associated with fraud from the first subset of datasets, a segmented first subset of data, wherein each dataset of the segmented first subset of datasets includes the first set of user characteristics associated with fraud,
select a third collection of datasets from the user data based on the new binary target variable, wherein each dataset included in the third collection of datasets is associated with at least one user characteristic associated with fraud,
determine, via a second iteration of the decision tree model, a second subset of datasets of the third collection of datasets, wherein each dataset included in the second subset of datasets is associated with a second set of user characteristics associated with fraud,
determine whether an accuracy score associated with the second set of user characteristics satisfies an accuracy precision threshold,
in response to determining that the accuracy score satisfies the accuracy precision threshold, generate and transmit a report for display to a user, the report including the second set of user characteristics,
receive, from a user computing device, user interaction data gathered during a user session, and
output, using the decision tree model and based on the second set of user characteristics and the user interaction data gathered during the user session, an indication that the user session is associated with fraudulent activity.
|