| CPC G06N 3/08 (2013.01) [G06F 40/10 (2020.01); G06N 3/045 (2023.01)] | 20 Claims |
|
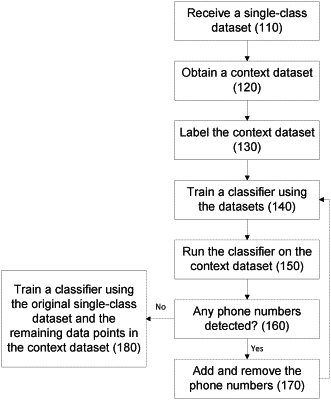
1. A non-transitory computer-accessible medium having stored thereon computer-executable instructions for generating a first dual-class dataset, wherein, when a computing hardware arrangement executes the instructions, the computing arrangement is configured to perform procedures comprising:
(a) accessing a first dataset including data points belonging to a first category of data points;
(b) accessing a second dataset including data points belonging to the first category of data points and a second category of data points;
(c) labeling each data point in the first dataset with a first label to generate a first labeled dataset, and labeling each data point in the second dataset with a second label to generate a second labeled dataset;
(d) training a classification model using the first labeled dataset and the second labeled dataset;
(e) using the classification model, classifying each data point in the second labeled dataset as belonging to one of the first category of data points or the second category of data points;
(f) for each data point in the second labeled dataset classified as belonging to the first category of data points, removing the data point from the second dataset and adding the data point to the first dataset; and
(g) generating the first dual-class dataset using the first dataset and the second dataset.
|