| CPC G06F 9/4881 (2013.01) [G06N 3/063 (2013.01); G06N 3/08 (2013.01)] | 18 Claims |
|
1. A system comprising:
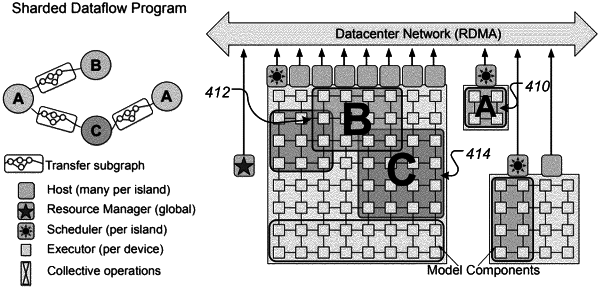
a plurality of accelerator islands, each accelerator island comprising a respective plurality of hardware devices that include a plurality of hardware accelerators and a corresponding host for each of the plurality of hardware accelerators, wherein the hardware accelerators within each accelerator island are interconnected with one another over an interconnect network, and are connected to the hardware accelerators within another accelerator island over a data center network through their corresponding hosts; and
a respective scheduler for each of the plurality of accelerator islands that is configured to schedule workloads across the plurality of accelerators and corresponding hosts in the accelerator island, wherein the system is configured to:
receive data representing a machine learning workload; and
assign a respective portion of the machine learning workload to each of the plurality of accelerator islands for scheduling by the respective scheduler for the accelerator island, wherein the respective scheduler is configured to, when the respective portion of the machine learning workload assigned to the accelerator island is a regular computation, schedule the respective portion of the machine learning workload using parallel asynchronous dispatch.
|