| CPC G06F 9/3879 (2013.01) [G06F 8/453 (2013.01); G06F 9/30174 (2013.01); G06F 9/3836 (2013.01); G06F 9/3851 (2013.01); G06F 9/3877 (2013.01); G06F 15/7807 (2013.01); G06F 17/16 (2013.01); G06N 20/00 (2019.01); G06N 20/10 (2019.01); G06F 9/3001 (2013.01); G06F 15/7864 (2013.01); G06F 15/8023 (2013.01); G06F 2212/602 (2013.01); G06N 5/04 (2013.01); G06N 20/20 (2019.01)] | 15 Claims |
|
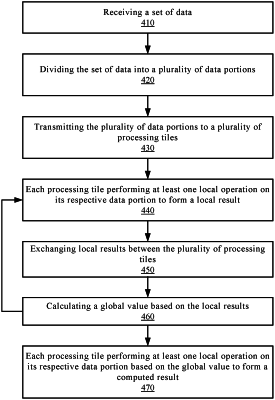
1. A computer implemented method, comprising:
receiving a set of data;
dividing the set of data into a plurality of data portions;
transmitting the plurality of data portions to a plurality of processing tiles, wherein each data portion of the plurality of data portions is associated with a processing tile of a plurality of tiles;
performing by each processing tile of the plurality of tiles at least one local operation on its respective data portion to form a local maxima;
exchanging local maximas between the plurality of processing tiles;
calculating a global maximum value based on the local maximas;
performing by each processing tile of the plurality of tiles a subtraction operation of the global maximum value from each data input its respective data portion to form a subtraction result;
performing by each processing tile of the plurality of tiles an exponential operation on the subtraction result to form exponential results;
forming a sum of the exponential results from the plurality of tiles; and
inverting the sum to form a scaled value.
|