| CPC G06F 40/58 (2020.01) [G06F 3/165 (2013.01); G06F 40/289 (2020.01); G10L 13/02 (2013.01)] | 18 Claims |
|
1. An electronic device comprising:
a speaker;
a memory configured to store at least one instruction; and
a processor electronically configured to execute the at least one instruction to:
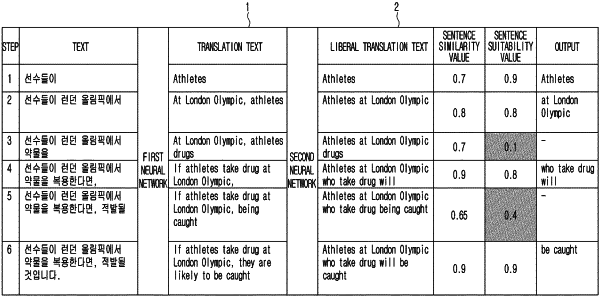
input a first text in a first language into a first neural network model and acquire a first translation text corresponding to the first text, the first translation text being in a second language that is different from the first language;
input the first translation text into a second neural network model and acquire a first liberal translation text corresponding to the first translation text, the first liberal translation text being a text obtained by including at least one that is different from words included in the first translation text and/or rearranging words included in the first translation text;
identify whether the first liberal translation text is to be output based on a sentence similarity value between the first translation text and the first liberal translation text, and further based on a sentence suitability value of the first liberal translation text, to obtain a first identification result;
selectively control the speaker to output a sound corresponding to the first liberal translation text based on whether the first identification result indicates that the first liberal translation text is to be output;
based on a second text being received subsequently to the first text, input the first text and the second text into the first neural network model and acquire a second translation text corresponding to the first text and the second text; and
input the first identification result and the second translation text into the second neural network model and acquire a second liberal translation text corresponding to the second translation text, the second liberal translation text being a text obtained by including at least one that is different from words included in the second translation text and/or rearranging words included in the second translation text, and
wherein the second neural network model is configured to:
based on identifying that the sound corresponding to the first liberal translation text was previously output via the speaker, according to the first identification result, output the second liberal translation text corresponding to the second translation text, the second liberal translation text including the first liberal translation text, which is located in front in a word order in the second liberal translation text; and
based on identifying that the sound corresponding to the first liberal translation text was not previously output via the speaker, according to the first identification result, output the second liberal translation text corresponding to the second translation text, the second liberal translation text not including the first liberal translation text in front in a word order in the second liberal translation text.
|