| CPC G06F 40/58 (2020.01) [G06F 40/237 (2020.01); G06F 40/284 (2020.01)] | 18 Claims |
|
1. A method for generating a destination vocabulary by a machine learning model, comprising:
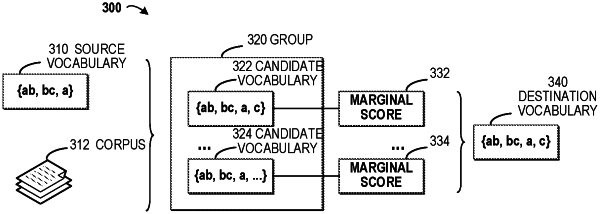
inputting a sequence of token candidates and data indicative of a training corpus into the machine learning model, the sequence of token candidates generated based on a source vocabulary, and the training corpus comprising texts in at least one language;
generating a group of candidate vocabularies at a plurality of timesteps by the machine learning model, the machine learning model is configured to generate optimal vocabularies with a computational efficiency by balancing a corpus entropy and a vocabulary size, wherein a size of a candidate vocabulary in the group of candidate vocabularies is different from a size of the source vocabulary;
computing a group of marginal scores corresponding to the group of candidate vocabularies, respectively, wherein a marginal score in the group of marginal scores corresponding to a candidate vocabulary in the group of candidate vocabularies is computed based on a corpus entropy of the candidate vocabulary and a size of the candidate vocabulary, wherein computing the marginal score comprises computing a negative derivation of the corpus entropy to the size of the candidate vocabulary, and wherein the computing a negative derivation of the corpus entropy to the size of the candidate vocabulary further comprises:
computing an entropy difference between the corpus entropy and a previous corpus entropy of a previous vocabulary, and
computing the negative derivation based on the entropy difference and a predefined step length; and
selecting the destination vocabulary from the group of candidate vocabularies based on the group of marginal scores.
|