| CPC G06F 40/289 (2020.01) [G06F 40/30 (2020.01)] | 9 Claims |
|
1. A method, comprising:
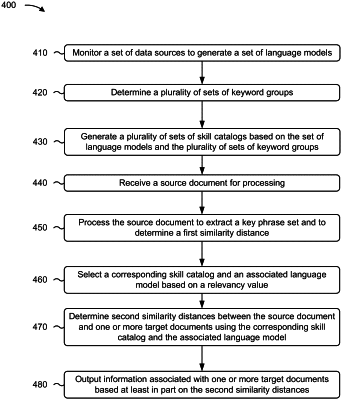
monitoring, by a device, a set of data sources to obtain data sets comprising corpuses;
generating, by the device, from the corpuses and by applying an artificial intelligence natural language processing technique, a set of language models corresponding to the set of data sources, each language model relating to specific job descriptions that include descriptions of specific skills;
determining, by the device using the artificial intelligence natural language processing technique applied to the set of language models, a plurality of sets of keyword groups for the set of language models such that each language model, of the set of language models, is associated with a corresponding set of keyword groups based on each language model relating to the specific job descriptions;
generating, by the device, a plurality of sets of skill catalogs based on the set of language models and the plurality of sets of keyword groups, such that each keyword group is associated with a skill catalog of the plurality of sets of skill catalogs, and such that each language model, of the set of language models, is associated with a corresponding set of skill catalogs, wherein each skill catalog includes a set of words for identifying skills, and wherein the set of words are extracted from a linguistic neighborhood of a keyword of a keyword group, using the language model and using the keyword group corresponding to the language model;
receiving, by the device, a source document for processing;
processing, by the device, the source document, wherein processing the source document includes extracting a key phrase set and determining, for each key phrase of the key phrase set, a first similarity distance to each skill of a corresponding skill catalog of the plurality of sets of skill catalogs, wherein extracting the key phrase set includes extracting the key phrase set from the source document using the language model, and wherein determining the first similarity distance includes:
determining a linguistic similarity distance between each key phrase of the key phrase set and each element of a skill catalog, each element including at least one of a word, a phrase, a sentence, or a document segment, and
aggregating linguistic similarity distances to determine an aggregate linguistic similarity distance that represents a relevancy value of the skill catalog to the source document;
selecting, by the device, the corresponding skill catalog and an associated language model based on the relevancy value;
obtaining, by the device, one or more target documents;
processing, by the device, the one or more target documents, wherein processing the one or more target documents includes extracting a key phrase set of the one or more target documents using the associated language model;
determining second similarity distances between the source document and the one or more target documents using the corresponding skill catalog and the associated language model, wherein the second similarity distances represent a set of linguistic similarity distances between elements of the corresponding skill catalog and the key phrase set of the one or more target documents; and
outputting information associated with one or more target documents based at least in part on the second similarity distances.
|