| CPC G06F 40/226 (2020.01) [G06F 18/214 (2023.01); G06F 40/169 (2020.01); G06N 3/04 (2013.01); G10L 15/063 (2013.01); G10L 15/075 (2013.01); G10L 15/16 (2013.01); G10L 15/18 (2013.01); G06F 40/279 (2020.01); G06F 40/295 (2020.01); G10L 2015/0635 (2013.01); G10L 15/1822 (2013.01); G10L 15/183 (2013.01)] | 2 Claims |
|
1. A method of training a neural network as a natural language processing, NLP, model, the method comprising:
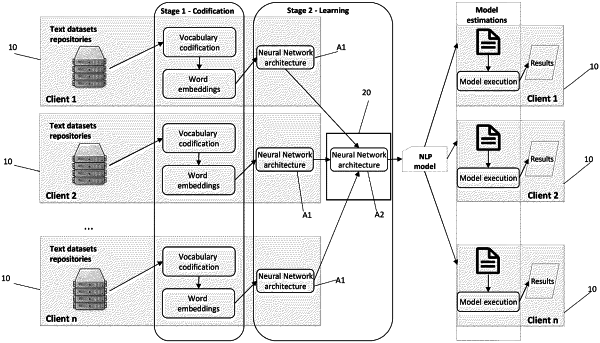
inputting respective sets of annotated training data to a plurality of first architecture portions of the neural network, which first architecture portions are executed in respective client computing devices of a plurality of distributed client computing devices in communication with a server computing device, wherein each set of training data is derived from a set of text data which is private to the client computing device in which the first architecture portion is executed, the server computing device having no access to any of the private text data sets, and all sets of training data share a common encoding;
deriving from the sets of annotated training data, using the first architecture portions, respective weight matrices of numeric weights which are decoupled from the private text data sets;
concatenating, in a second architecture portion of the neural network which is executed in the server computing device, the weight matrices received from the client computing devices to obtain a single concatenated weight matrix; and
training, on the second architecture portion, the NLP model using the concatenated weight matrix;
wherein the sets of training data in the common encoding are derived by pre-processing private sets of text data in respective client computing devices by:
carrying out on the set of text data in each client computing device a vocabulary codification process to ensure a common vocabulary codification amongst all the training data to be provided by the client computing devices, wherein in the vocabulary codification process a common alphanumeric character-level representation is established for the vocabulary that uses characters decided by the server computing device, and
using the predefined common character-level representations and predefined common setting parameters, carrying out in each client computing device a word embedding process in which the text data is mapped to vectors of real numbers.
|