| CPC G06F 18/2137 (2023.01) [G06N 3/088 (2013.01)] | 20 Claims |
|
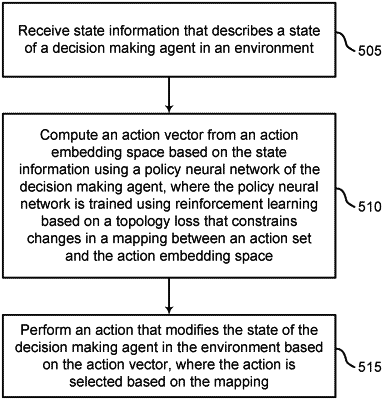
1. A method of machine learning, comprising:
receiving, by a monitoring component, state information that describes a state of a decision making agent in an environment;
computing, using a policy neural network of the decision making agent, an action vector from an action embedding space based on the state information, wherein the policy neural network is trained using reinforcement learning based on a topology loss that constrains changes in a mapping between an action set and the action embedding space; and
performing, by the decision making agent, an action that modifies the state of the decision making agent in the environment based on the action vector, wherein the action is selected based on the mapping.
|