| CPC G06F 18/2113 (2023.01) [G06F 17/18 (2013.01); G06F 18/22 (2023.01); G06F 18/232 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
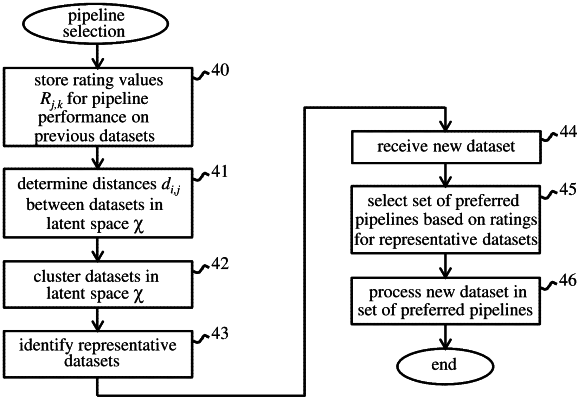
1. A computer-implemented method for selecting preferred machine learning pipelines for processing new datasets, the method comprising:
for a plurality of machine learning pipelines and a plurality N of datasets previously-processed by the pipelines, storing a plurality of rating values, each rating value corresponding to a performance of a pipeline of the plurality of machine learning pipelines and for a dataset of the plurality N of datasets;
for each pair ui=1 to N, uj=1 to N, i±j of the plurality N of previously-processed datasets, determining a distance di,j from ui to uj in a latent space, wherein the distance di,j corresponds to an expected value of a regret incurred when the pipeline, selected in a predetermined manner based on a set of rating values for a dataset uj, is rated for a performance of the selected pipeline for a dataset ui, and wherein the regret for the selected pipeline includes a monotonically decreasing function of the rating value for the performance of the pipeline for the dataset ui,
clustering the plurality N of previously-processed datasets in the latent space and identifying a representative dataset in each cluster for which each distance to the dataset from other datasets in the cluster is minimized over the cluster;
in response to receiving a new dataset, selecting a set of preferred pipelines from the plurality of machine learning pipelines for processing the new dataset, each preferred pipeline being selected according to a set of rating values for the representative dataset; and
processing the new dataset in the set of preferred pipelines.
|