| CPC G06F 16/906 (2019.01) [G06F 16/9035 (2019.01); G06F 16/9038 (2019.01); H04L 45/02 (2013.01)] | 20 Claims |
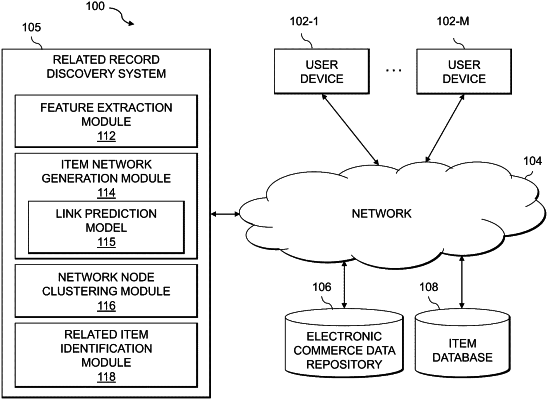
|
1. A method, comprising:
obtaining a plurality of data records, wherein each data record corresponds to a different one of a plurality of items and comprises a plurality of features extracted from at least one data source, wherein at least one data record associated with a first item identifies at least one related item that is related to the first item, wherein the at least one related item is identified in the plurality of data records using a collaborative filter that relates at least some of the items of the plurality of items based at least in part on preferences of a plurality of users, and wherein the collaborative filter identifies, for a given item, one or more additional items obtained or researched by one or more users that also obtained or researched, respectively, the given item;
generating, using the plurality of data records, an item network comprising a plurality of nodes, wherein each node in the item network corresponds to a different one of the plurality of items, wherein two nodes in the item network are selectively connected by an edge in response to an evaluation of: (i) an item type of the items associated with the two nodes, (ii) a ratio of numerical values associated with the two nodes, and (iii) a pairwise configuration similarity score for the two nodes, wherein the pairwise configuration similarity score for the two nodes is based at least in part on a similarity analysis of a textual description of a configuration of each of the items associated with the two nodes, extracted from the at least one data source, for each of the two nodes, wherein the two nodes in the item network are selectively connected by the edge in response to the evaluation determining that: (i) the respective item types of the items associated with the two nodes satisfy one or more similarity criteria, (ii) the ratio of the numerical values associated with the two nodes satisfies a first designated threshold, and (iii) the pairwise configuration similarity score for the two nodes satisfies a second designated threshold, wherein the first designated threshold and the second designated threshold are distinct and wherein the ratio of the numerical values is distinct from the pairwise configuration similarity score;
clustering the plurality of nodes in the item network into a plurality of node clusters based at least in part on an analysis of one or more topological properties of the item network;
identifying one or more items related to a given item by querying the item network to return the one or more identified related items having a corresponding node in the item network that (i) shares an edge with a node in the item network corresponding to the given item and (ii) are in at least one node cluster comprising a node corresponding to the given item; and
initiating an automated processing of at least a given one of the plurality of data records associated with the given item using at least some of the identified one or more items related to the given item;
wherein the method is performed by at least one processing device comprising a processor coupled to a memory.
|