| CPC G06F 13/1668 (2013.01) [G06F 13/28 (2013.01); G06T 1/20 (2013.01); H04N 5/765 (2013.01)] | 20 Claims |
|
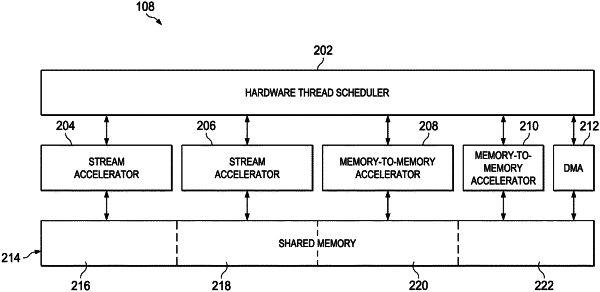
1. A processing accelerator, comprising:
a thread scheduler;
a stream accelerator coupled to the thread scheduler;
a shared memory; and
a memory controller coupled to the shared memory;
wherein the stream accelerator includes processing circuitry, and a load/store engine coupled to the processing circuitry, the load/store engine including a buffer, and shared memory access circuitry.
|
|
17. A processing accelerator, comprising:
a thread scheduler;
a hardware accelerator coupled to the thread scheduler;
a shared memory having a depth that is configurable; and
a memory controller coupled to the shared memory;
wherein the depth of the shared memory is configurable based on one of a size of data, a format of data, and a transfer latency.
|
|
18. A method, comprising:
receiving, by a first hardware accelerator, a first set of data;
processing, by the first hardware accelerator, the first set of data to generate a first output data;
storing, by the first hardware accelerator, the first output data in a shared memory coupled to a second hardware accelerator;
retrieving, by the second hardware accelerator, the first output data from the shared memory;
processing, by the second hardware accelerator, the first output data to produce a second output data;
storing, by the second accelerator, the second output data in the shared memory; and
synchronizing, by a scheduler coupled to the first hardware accelerator and the second hardware accelerator, the retrieving of the first output data stored in the shared memory by the second hardware accelerator based on availability of the first output data in the shared memory.
|
|
20. A method, comprising:
receiving by a first hardware accelerator, a first set of data;
processing, by the first hardware accelerator, the first set of data to generate first output data;
storing, by the first hardware accelerator, the first output data in a shared memory coupled to a second hardware accelerator;
retrieving, by the second hardware accelerator, the first output data from the shared memory;
processing, by the second hardware accelerator, the first output data to produce second output data; and
storing, by the second accelerator, the second output data in the shared memory;
wherein the shared memory includes a first variable depth circular buffer accessible by the first hardware accelerator; and
wherein the shared memory includes a second variable depth circular buffer accessible by the second hardware accelerator.
|