| CPC G05B 13/027 (2013.01) [F24F 11/62 (2018.01); G05B 15/02 (2013.01); G06N 3/088 (2013.01)] | 15 Claims |
|
1. A processor implemented method, comprising:
obtaining, via one or more hardware processors, input data comprising (i) a design specification of one or more controllable electrical equipment installed and operating in a building and (ii) design details of the building associated thereof;
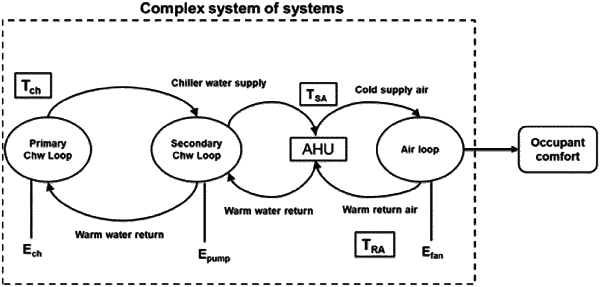
generating, via the one or more hardware processors, a simulation model using the input data, wherein the simulation model is built in offline by abstracting complex Heating, ventilation, and air conditioning (HVAC) loops of the building into three loops wherein the three loops are a primary chilled water loop, a secondary chilled water loop, and an air loop, and an energy consumption of the primary loop is Ech, an energy consumption of the secondary loop is Epump, an energy consumption of the air loop is Efan;
training, via the one or more hardware processors, a plurality of deep Reinforcement learning (RL) agents using the generated simulation model, wherein the plurality of deep RL agents interacts with an environment of the building and learns to act using a Markov Decision Process (MDP) method;
deploying, via the one or more hardware processors, each of the plurality of trained deep RL agents in the one or more controllable electric equipment of the building, wherein
the primary chilled water loop is assigned with a first deep trained RL agent of the plurality of trained deep RL agents,
the secondary chilled water loop is assigned with a second deep trained RL agent of the plurality of trained deep RL agents, and
the air loop is assigned with a third deep trained RL agent of the plurality of trained deep RL agents,
each of the plurality of trained deep RL agents monitors one or more states affecting performance of the one or more controllable electric equipment in the building,
during an execution of each of the plurality of trained RL agents, a reward function is assigned to each of the plurality of trained RL agents,
the reward function comprises an energy component of the one or more controllable electrical equipment and a penalty,
the reward function comprises an energy component, and
the penalty includes a visual feedback of an associated controllable electrical equipment and degradation information of the associated controllable electrical equipment,
the reward function of the first deep trained RL agent is r1=Ech+a factor*the visual feedback,
the reward function of the second deep trained RL agent is r2=Epump+the factor*Ech, and
the reward function of the third deep trained RL agent is r3=Efan+a factor1*the visual feedback+a factor2*Ech;
triggering, via the one or more hardware processors, each of the plurality of trained deep RL agents, to obtain a portion of the reward function associated with another deep RL agent, wherein
a first trained deep RL agent of the plurality of trained deep RL agents obtains a first specific portion of the portion of the reward function from a second trained deep RL agent of the plurality of trained deep RL agents,
the first specific portion of the reward function includes the energy component only, the penalty only or combination of both the energy component and the penalty,
the first specific portion of the reward function include the energy component and the penalty,
the first trained deep RL agent is associated with a first controllable electrical equipment of the one or more controllable electrical equipment,
the second trained deep RL agent is associated with a second controllable electrical equipment of the one or more controllable electrical equipment, and
information on the portion of the reward function is utilized for training the plurality of trained deep RL agents;
estimating, via the one or more hardware processors, based on the obtained portion of the reward function, a global optimal control parameter list based on an optimal control parameter associated with each of the plurality of trained deep RL agents, wherein the optimal control parameter is learnt by each of the plurality of trained deep RL agents during an execution of the plurality of trained deep RL agents deployed in the one or more controllable electric equipment in the building, wherein the optimal control parameter comprises scheduling information of the associated controllable electrical equipment; and
fine tuning a plurality of control parameters of the global optimal control parameter list to improve a performance of each of the plurality of trained deep RL agents.
|