| CPC B25J 9/163 (2013.01) [B25J 9/1661 (2013.01); B25J 9/1664 (2013.01); B25J 9/1697 (2013.01); G05B 13/027 (2013.01); G05B 13/04 (2013.01); G06N 3/08 (2013.01); G06N 5/046 (2013.01); G06N 20/00 (2019.01)] | 30 Claims |
|
1. A computer-implemented method, comprising:
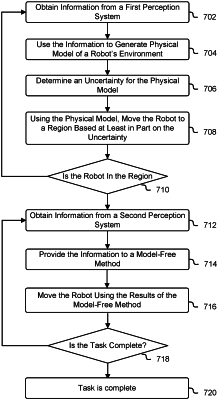
dividing at least a portion of a physical model created based at least in part on information from a perception system into a plurality of regions;
generating estimates of uncertainty for the plurality of regions based at least in part on at least one uncertainty estimation provided by the perception system;
using the physical model to control a robot in any of the plurality of regions associated with any of the estimates of uncertainty that indicate the robot is unlikely to interact with its environment; and
using at least one reinforcement learning process instead of using the physical model to control the robot in any of the plurality of regions associated with any of the estimates of uncertainty that indicate the robot is likely to interact with its environment.
|