| CPC G10L 25/30 (2013.01) [G10L 15/16 (2013.01); G10L 15/20 (2013.01); G10L 19/008 (2013.01); G10L 21/028 (2013.01); G10L 21/0388 (2013.01); G10L 2021/02087 (2013.01); G10L 2021/02166 (2013.01)] | 20 Claims |
|
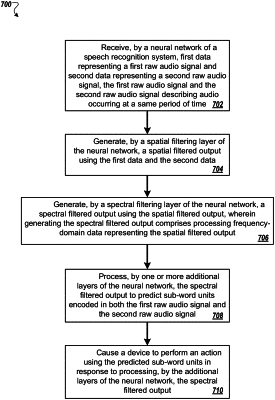
1. A computer-implemented method when executed on data processing hardware causes the data processing hardware to perform operations comprising:
receiving multi-channel audio data representing an utterance captured by multiple microphones during a same period of time, the multi-channel audio input comprising multiple time-domain audio signals each obtained from a respective one of the multiple microphones, the multiple microphones located at different spatial position with respect to a user that spoke the utterance;
for each of multiple spatial directions, generating a corresponding spatial filtered output by processing each time-domain audio signal among the multiple time-domain audio signals of the multi-channel audio input;
predicting sub-word units encoded in the time-domain audio signals for respective portions of the utterance by processing a frequency-domain representation of the corresponding spatial filtered output generated for each of the multiple spatial direction; and
generating a transcription for the utterance based on the predicted sub-word units encoded in the time-domain audio signal for the respective portions of the utterance.
|