| CPC G06T 5/50 (2013.01) [G06N 3/02 (2013.01); G06T 7/194 (2017.01); G06T 11/00 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01)] | 9 Claims |
|
1. A method for image processing, comprising:
obtaining a mask by separating an original image into a background image and a foreground image;
obtaining a partial stylized image by transforming, the foreground image according to a selected style without transforming the background image; and
obtaining, a stylized image according to the mask and the partial stylized images;
wherein obtaining the partial stylized image by transforming, the foreground image according to the selected style without transforming the background image comprises transforming the foreground image according to the selected style with an image transformation network to obtain the partial stylized image;
wherein prior to obtaining the mask, the image transformation network is trained with perceptual loss functions defined by a loss network;
wherein the loss network is a visual geometry group (VGG) network having a plurality of convolutional layers;
wherein training the image transformation network with perceptual loss functions defined by the loss network comprises:
using values of the perceptual loss functions as activations of one of the plurality convolutional layers of the loss network according to the following formula:
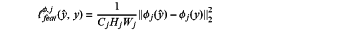 wherein:
j represents a jth convolutional layer;
Cj represents a number of channels input into the jth convolutional layer;
Hj represents a height of the jth convolutional layer;
Wj represents a width of the jth convolutional layer; and
φj(x) represents a feature map of shape Cj×Hj×Wj.
|