| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01); G06N 3/045 (2023.01)] | 20 Claims |
|
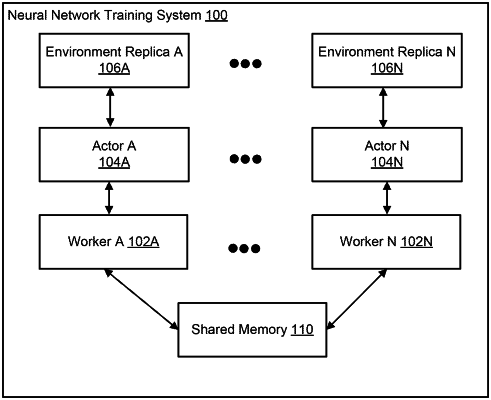
1. A method of training a deep neural network having a plurality of parameters that is used to select actions to be performed by an agent that interacts with an environment by performing actions selected from a predetermined set of actions, the method comprising:
using a plurality of workers to generate training data for training the parameters of the deep neural network;
wherein for each worker:
the worker is configured to operate independently of each other worker;
the worker is associated with a respective actor that interacts with a respective replica of the environment in accordance with a respective exploration policy;
the exploration policy is parameterized by a set of exploration policy parameters, wherein values of the exploration policy parameters are specific to the worker and are different from values of exploration policy parameters of each of one or more other workers of the plurality of workers; and
wherein each worker is configured to generate training data by repeatedly performing operations comprising:
determining current values of the parameters of the deep neural network;
receiving a current observation characterizing a current state of the environment replica interacted with by the actor associated with the worker;
selecting a current action to be performed by the actor associated with the worker in response to the current observation in accordance with the exploration policy for the worker and using one or more outputs generated by the deep neural network in accordance with the current values of the parameters of the deep neural network;
identifying an actual reward resulting from the actor performing the current action when the environment replica is in the current state;
receiving a next observation characterizing a next state of the environment replica interacted with by the actor, wherein the environment replica transitioned into the next state from the current state in response to the actor performing the current action; and
adding the current action, the actual reward, and the next observation to the training data generated by the worker;
applying a reinforcement learning technique to the training data generated by each of the plurality of workers to determine one or more current gradients; and
determining updated values of the parameters of the deep neural network using the current gradients.
|