| CPC G06F 16/285 (2019.01) [G06N 20/00 (2019.01); G06V 30/19173 (2022.01); G16H 15/00 (2018.01)] | 24 Claims |
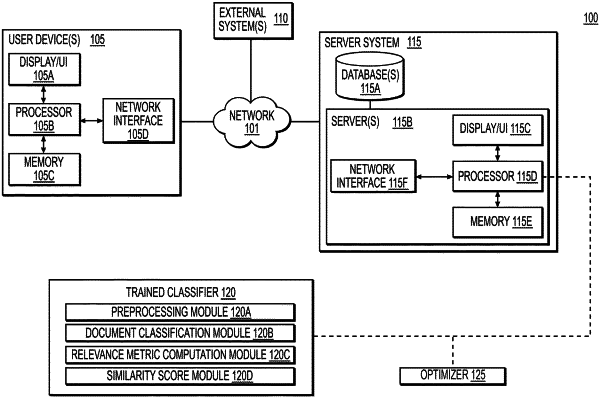
|
1. A computer-implemented method for extracting information from a dataset, comprising:
receiving, at an information handling device, a dataset;
extracting, via optical character recognition implemented by a processor of the information handling device, textual information associated with the dataset; and
classifying the dataset into one of a plurality of classes, the classifying further comprising:
computing a similarity score for each of the plurality of classes for each of a plurality of window regions of the dataset, the computing further comprising:
sliding a window across the textual information to define the plurality of window regions, and for each of the plurality of window regions:
computing a relevance metric for the window region; and
calculating the similarity score for each of the plurality of classes by calculating a similarity function between the relevance metric for the window region and an average relevance metric for each of the plurality of classes;
determining, based on a subset of highest similarity scores computed for each of the plurality of classes for each of the plurality of window regions, overall similarity scores for each of the plurality of classes for the dataset; and
classifying the dataset as corresponding to a class of the plurality of classes with a highest overall similarity score for the dataset.
|