| CPC H04N 13/275 (2018.05) [G06T 7/60 (2013.01); G06T 7/75 (2017.01); H04N 13/282 (2018.05); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30196 (2013.01); G06T 2210/16 (2013.01); G06T 2210/21 (2013.01)] | 14 Claims |
|
1. A processor implemented method for draping a 3D garment on a 3D human body, the method comprising:
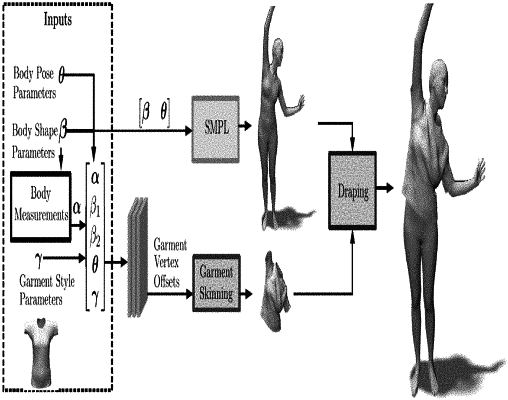
receiving, via a one or more hardware processors, a plurality of human body inputs which includes data representation of a subject;
creating, using a skinned multi person linear (SMPL) model, via the one or more hardware processors, a 3D human body of the subject based on a body shape (β), and a body pose (θ) of the plurality of human body inputs;
predicting, using a multi-layer perceptron model, via the one or more hardware processors, garment vertex offsets based on the plurality of human body inputs,
wherein the plurality of human body inputs includes the subject's (i) body shape (β), (ii) body measurements (α), (iii) body pose (θ), and (iv) garment style coefficient (y);
constructing, using a garment skinning function, via the one or more hardware processors, 3D skinned garments for the subject using the garment vertex offsets; and
draping, using a trained deep draper network, via the one or more hardware processors, the 3D skinned garments on the 3D human body of the subject based on
(i) the garment vertex offsets, and
(ii) a plurality of pre-defined ground truth garment intermediate features obtained from the trained deep draper network, wherein the deep draper network is trained based on a plurality of losses,
wherein training the deep draper network comprises:
constructing a plurality of training data inputs for the deep draper network from one or more subjects, wherein the plurality of training data inputs includes (i) training data body measurements (α), (ii) a training data body shape (β), (iii) a training data body pose (θ), and (iv) training data garment style coefficients (Y);
predicting, using a multi-layer perceptron model, the garment vertex offsets (Ó) and a garment vertex normal based on the plurality of training data inputs and trained model parameters, wherein each training data body shape includes a first body coefficient and a second coefficient;
predicting 3D skinned garment images by applying (i) the garment skinning function on the garment vertex offsets, (ii) the training data body pose, (iii) the training data body shape, (iv) the training data body measurements, and (v) the training data garment style coefficients;
assigning a texture (T) to each predicted 3D skinned garment vertex offset as a function of its unit texture normal (ni);
generating, using a multiview garment rendering model, a multi view of the 3D skinned garment images to exploit correlations between each high frequency garment in 3D with its corresponding rendered image using (i) the garment vertex normal, (ii) a front view rendered garment image, (iii) a back view rendered garment image, (iv) a right view rendered garment image, (v) a left view rendered garment image, and (vi) a top view rendered garment image;
feeding the multi views of the 3D skinned garment images as input to a VGG19 network to predict garment intermediate features;
comparing the predicted garment intermediate features with the plurality of pre-defined ground truth garment intermediate features to obtain a perceptual loss corresponding to each multi view of the 3D skinned garment images; and
updating the multi-layer perceptron model of the deep draper network based on the plurality of losses comprising (i) a perceptual loss, (ii) a geometric data loss, (iii) a body garment collision loss, and (iv) an image content loss.
|