| CPC G10L 15/22 (2013.01) [G06N 20/00 (2019.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A system comprising:
a server having at least one data store and at least one computer processor, wherein the server is in communication with at least one smart speaker over one or more networks, and
wherein the server is programmed with one or more sets of instructions that, when executed by the processor, cause the server to perform a method comprising:
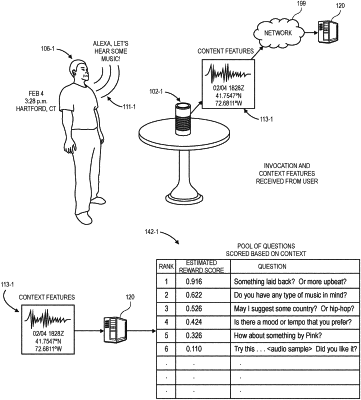
receiving first data from a first smart speaker over the one or more networks, wherein the first data comprises:
first audio data captured by one or more sensors of the first smart speaker; and
at least a first context feature regarding one of the first audio data captured by one or more sensors of the first smart speaker or a first user of the first smart speaker;
determining that the first audio data comprises a first invocation to initiate a first conversation;
in response to determining that the first audio data comprises the first invocation,
determining a first context of the first invocation based at least in part on the first context feature; and
determining scores of each of a first set of questions based at least in part on the first context, wherein each of the scores is a probability that one of the first set of questions will cause the first conversation to have a successful outcome;
transmitting second data for presenting a first question of the first set of questions to the first smart speaker over the one or more networks, wherein the first question has a highest score of the first set of questions;
receiving third data from the first smart speaker over the one or more networks;
determining a first outcome of the first conversation based at least in part on the third data;
receiving fourth data from a second smart speaker of the plurality of smart speakers over the one or more networks, wherein the fourth data comprises:
second audio data captured by one or more sensors of the second smart speaker; and
at least a second context feature regarding one of the second audio data captured by one or more sensors of the second smart speaker or a second user of the second smart speaker;
determining that the second audio data comprises a second invocation to initiate a second conversation;
in response to determining that the second audio data comprises the second invocation,
determining a second context of the second invocation based at least in part on the second context feature; and
determining scores of each of a second set of questions based at least in part on the second context, wherein each of the scores is a probability that one of the second set of questions will cause the second conversation to have a successful outcome;
selecting a second question of the second plurality of questions according to a randomization policy;
transmitting fifth data for presenting the second question to the second smart speaker over the one or more networks;
receiving sixth data from the second smart speaker over the one or more networks;
determining a second outcome of the second conversation based at least in part on the sixth data;
training a machine learning model to score questions based on a context of an invocation using a training set of data comprising:
the third data;
the first outcome;
the sixth data; and
the second outcome.
|