| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01); G09G 5/37 (2013.01)] | 20 Claims |
|
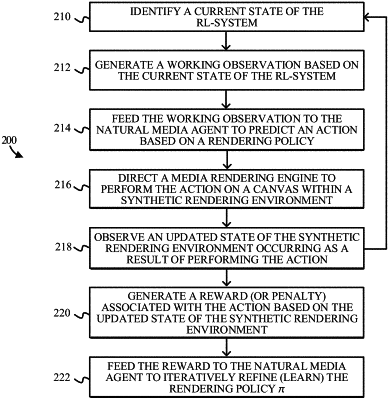
1. One or more non-transitory computer readable media for training a natural media agent to implicitly learn a rendering policy in a multi-dimensional continuous action space from a set of training references, the one or more non-transitory computer readable media comprising instructions that, when executed by at least one processor of a reinforcement learning-based system, iteratively cause the system to:
direct a media rendering engine to perform at least one primitive graphic action on a canvas in a synthetic rendering environment, wherein the natural media agent is configured to apply the rendering policy to select the at least one primitive graphic action at each iteration based on a working observation of a current state of the system;
observe a visual state of the canvas and a position of a media rendering instrument within the synthetic rendering environment occurring as a result of performing the at least one primitive graphic action on the canvas;
apply a loss function to compute a reward based on a goal configuration and the visual state of the canvas occurring as a result of performing the at least one primitive graphic action, wherein the goal configuration comprises a current training reference of the set of training references; and
provide the reward to the natural media agent to learn the rendering policy by refining a policy function.
|