| CPC G06F 40/40 (2020.01) [G06F 40/289 (2020.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A method for processing information, the method comprising:
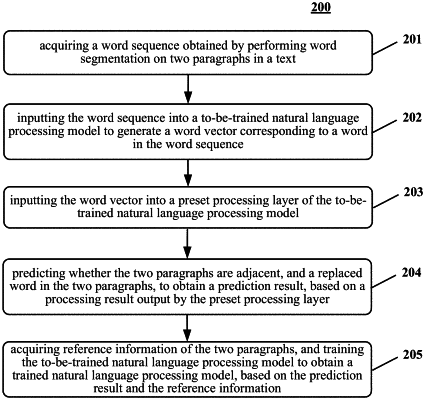
acquiring a word sequence obtained by performing word segmentation on two paragraphs in a text, wherein the word sequence comprises at least one specified identifier for replacing a first word;
inputting the word sequence into a to-be-trained natural language processing model to generate a word vector corresponding to a second word in the word sequence, wherein the word vector is used to represent the second word in the word sequence and a position of the second word;
inputting the word vector into a preset processing layer of the to-be-trained natural language processing model, wherein the preset processing layer comprises an encoder and a decoder;
predicting whether the two paragraphs are adjacent, and the replaced first word in the two paragraphs, to obtain a prediction result, based on a processing result output by the preset processing layer;
acquiring reference information of the two paragraphs, and training the to-be-trained natural language processing model to obtain a trained natural language processing model, based on the prediction result and the reference information, wherein the reference information comprises adjacent information indicating whether the two paragraphs are adjacent, and the replaced first word;
acquiring first sample information, wherein the first sample information comprises a first paragraph word sequence obtained by performing word segmentation on a first target paragraph, and a first specified attribute;
inputting the first sample information comprising the first paragraph word sequence and the first specified attribute into the trained natural language processing model to predict correlation information, wherein the correlation information is used to indicate a correlation value between the first paragraph word sequence and the first specified attribute, and the correlation value is determined by determining whether the first specified attribute or a meaning of the first specified attribute is included in the first paragraph word sequence; and
training the trained natural language processing model to obtain a first model, based on predicted correlation information and correlation information for labeling the first sample information, wherein a loss value is calculated based on the correlation information for labeling the first sample information and the predicted correlation information to implement further training of the trained natural language processing model.
|